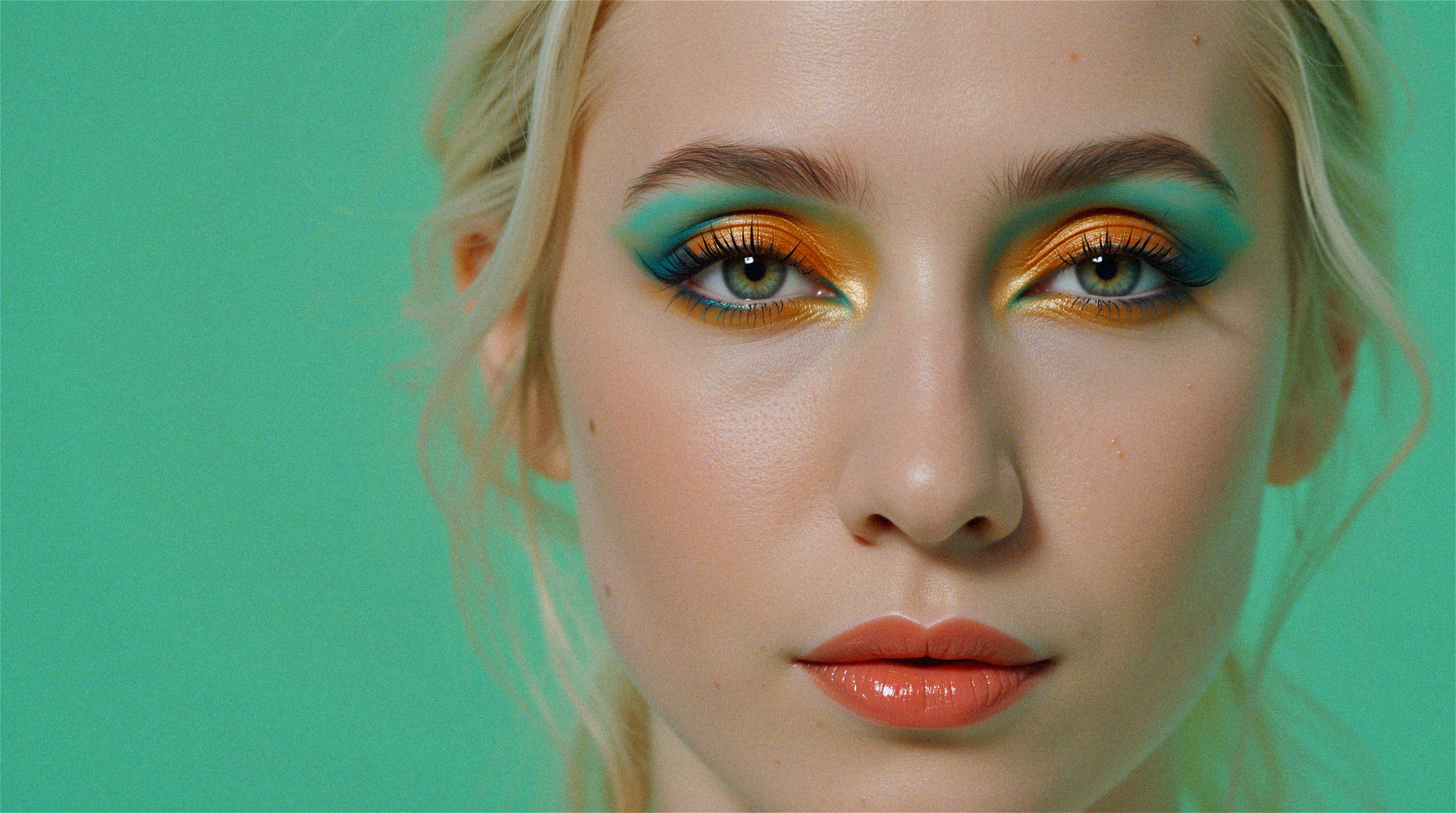
Wan & SkyReels Text to Image Workflows

About this model
📷 HD IMAGE OUTPUT – Now with ControlNet & Img2Img! (Up to 2048P)
🌀 SkyReels and WAN – Text-to-Video Models, Stunning Still Results
Sharing my current workflows for WAN and SkyReels — both are text-to-video models, but they generate incredible still images too.
⚙️ Defaults work great, but everything’s tweakable.
📝 Don’t skip the in-workflow notes — they cover setup and tips.
💡 Running with under 16GB VRAM? Enable block swapping for smoother runs.
🚀 Want faster speed? Drop steps to 4. The examples here used 10 steps and ran in ~25 seconds on an RTX 5090.
🔥 After lots of testing, I’m getting better results than FLUX — faces are more realistic, and no FLUX face issues.
To Simplify things you can just swap models out instead of having two separate workflows for each model. The links to the models are in the workflows.
☕ Like what I do? Support me here: Buy Me A Coffee 💜
Every coffee helps fuel more free LoRAs & workflows!
❓What’s the difference between these two workflows?
Glad you asked! After plenty of testing:
🎬 SkyReels gives a slightly more cinematic and realistic look.
🌟 WAN is a bit sharper and punchier, but not as cinematic.
That said, LoRA choice heavily affects output, so I recommend trying both workflows with your prompts to see which one fits your style best.
🚧 These features currently work with the WAN wrapper:
🖊️ Text-to-Image
🧠 ControlNet (DepthAnything, DW Pose, Canny, Lineart, etc.)
🖼️ Image-to-Image (enhance/upscale with denoise control)
✅ Native support is available now — ControlNet and Image-to-Image coming soon!
✅ Native GGUF support is available now — ControlNet and Image-to-Image coming soon!
💭 Why do these look so good? Simple: they’re trained on video, meaning way more frames per concept — and WAN is a 14B model, much larger than FLUX. That scale and frame data really shows in the results.
Give them a spin and let me know what you think!
👉 Need help crafting text-to-image prompts? I made a GPT just for that: Perfect Text-to-Image Prompt Creator
Try them out and let me know what you think!
Related Models
Similar AI models you may like
ON-THE-FLY 实时生成!Wan-AI 万相/ Wan2.1 Video Model (multi-specs) - CausVid&Comfy&Kijai - workflow included

【WAN2.1】IMG to VIDEO

ComfyUI Image Workflows
WAN 2.2 Workflow T2V-I2V-T2I (Kijai Wrapper)

Hunyuan 🌻 AllInOne
Wan2.1_14B_FusionX

Moody Simple Zimage Turbo/Distilled Workflow
